1 简介
Gravity:I2C 离线语音识别模块,是一款以Gravity I2C作为连接接口的、针对中文进行识别的模块。该模块采用由 ICRoute 公司设计的 LD3320 “语音识别”专用芯片,只需要在程序中设定好要识别的关键词语列表并下载进主控的MCU中,语音识别模块就可以对用户说出的关键词语进行识别,并根据程序进行相应的处理。本品不需要用户事先训练和录音就可以完成非特定人语音识别,识别准确率高达95%。
- 针对误识别问题:建议将关键词设置为4-6个词左右,如将“kai deng”设置为“da kai deng guang”或“da kai ke ting deng”
- 针对识别率问题:一些前后鼻音模糊的词,可以将前后鼻音都添加到一个关键词,如设置“打开灯光”这个关键词
asr.addCommand("da kai deng guang",2);
asr.addCommand("da kai den guang",2);

- 太靠近麦克风识别效果会非常差,请离麦克风10cm以上
2 产品描述
-
Arduino兼容控制器:Arduino Uno、Arduino leonardo、Arduino MEGA、FireBeetle 系列控制器
-
支持
mind+编程 -
通过
Gravity I2C连接,简化方便,且兼容3.3V与5V -
通过 LD3320 芯片做汉语语音识别,不需要用户事先训练和录音,识别准确率 95%
-
每次识别最多可以设置 50 项候选识别句,识别句可以是
单字,词组或短句,长度为不超过 10 个汉字或者 79 个字节的拼音串 -
板载驻极体麦克风(咪头),可直接用于语音的拾取,无需要接入任何其他录音设备,方便使用
-
3.5mm 麦克风接口,可接入本品包装内附赠的 3.5mm 接口的领夹式麦克风,接入后则板载驻极体麦克风不工作
-
3.5mm 音频输入接口,具体使用方式可详见 5.4 小节
-
板载电源指示灯(红)和识别模式及状态指示灯(RGB)
-
三种不同的语音识别模式,满足不同的识别场景需求
3 产品参数
- 工作电压- :3.3~5V
- 工作电流:25 ~ 40 mA
- 板载麦克风灵敏度:-38db
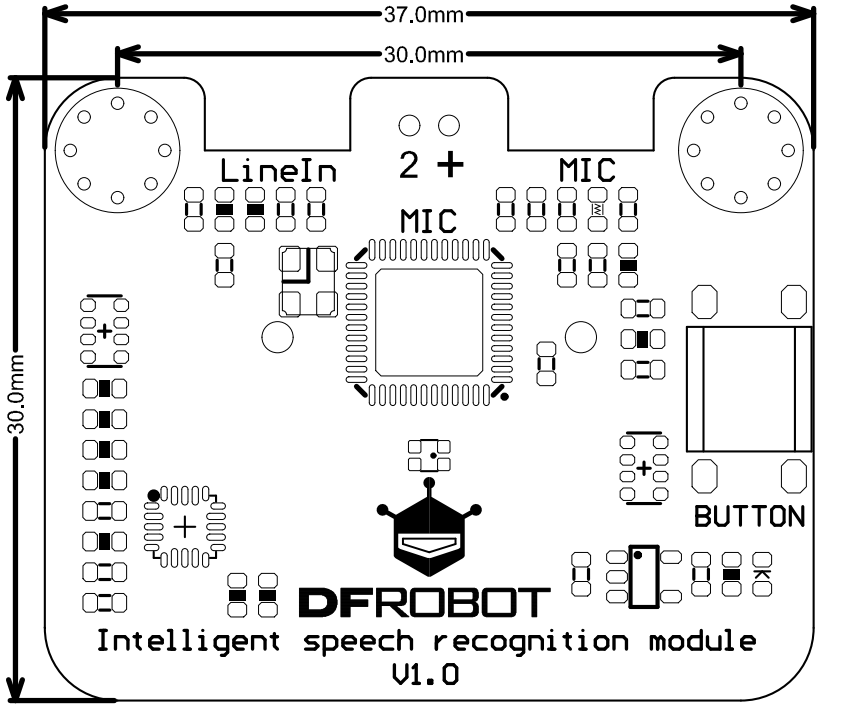
- 模块尺寸:37 * 30 mm
- 安装孔尺寸:内径3.1mm/外径6mm
- 重量:35g
4 引脚图
-
**板载麦克风:**板载麦克风的作用是拾取用户语音,有了板载麦克风,本品无需接入任何其他语音输入设备即可拾取声音。本品在默认状态下使用板载麦克风,当 3.5mm 耳机接口接入录音设备后,则自动屏蔽板载麦克风。
-
**3.5mm MIC 接口:**3.5mm 麦克风接口可以接入产品包装内附赠的领夹式麦克风或带有拾音功能的耳机,由于市面上耳机的接口标准存在不同,可能会出现无法拾音的现象,推荐使用本品附赠的领夹式麦克风。当 3.5mm 领夹式麦克风接入后,板载麦克风将被屏蔽。
-
**3.5mm LineIn 接口:**LineIn 接口只在本品设置为 MONO 模式下可用,具体使用方式请详见 5.4 小节
-
**6*6mm 按钮:**按钮只在本品设置为按钮模式下使用。在其他模式下按钮不工作。

特此说明:外接音频输入接口不是外置MIC,是线路输入口。
如果将外接音频音源接入MIC口,声音将出现失真。如果将MIC音源接入外接音频音源口,几乎没有声音。
麦克风输入信号是没有经过处理过的信号,电压一般在几毫伏到几百毫伏,而外接音频得电压通常是MIC信号电压的1000倍。
PS:如果外接MIC不能正常使用,可以尝试将3.5mm接头拔出一节
5 使用说明
5.1 语音控制LED灯实验
打开串口监控,设置好波特率,对着麦克风用标准的普通话说“打开灯光”,LED灯就会点亮,同时会通过串口推送指令标签“0”, 之后说“关闭灯光”,LED就会熄灭,同时会通过串口推送指令标签“1”。 PS:不要把嘴巴凑在话筒上..
硬件清单:
- 连接线若干
工具软件清单:
- Arduino IDE
连线图:

演示代码:
代码所需库文件 DFRobot_ASR
#include "DFRobot_ASR.h"
#define Led 8 //定义Led引脚为8
DFRobot_ASR asr;
void setup()
{
Serial.begin(9600);
pinMode(Led,OUTPUT); //初始化LED引脚为输出模式
digitalWrite(Led,LOW); //LED引脚低电平
/*
begin函数有两个参数:
1)设置语音识别模式:1.LOOP(默认,循环模式) 2.PASSWORD(指令模式) 3.BUTTON(按钮模式)
2)选择模块的录音输入方式:1.MIC(默认,此时板载咪头和3.5mm输入接口工作)2.MONO(3.5mm外接音频输入接口工作)
*/
asr.begin(asr.LOOP);
asr.addCommand("da kai deng guang",0);
asr.addCommand("guan bi deng guang",1);
//开始识别
asr.start();
Serial.println("Start");
}
void loop()
{
switch(asr.read()) //判断识别内容,在有识别结果的情况下asr.read()会返回识别到的词条编号,否则返回-1
{
case 0: //若是指令“da kai deng guang”
digitalWrite(Led,HIGH); //点亮LED
Serial.println("received'da kai deng guang',command flag'0'");//串口发送received"kai deng",command flag"0"
break;
case 1: //若是指令“guan bi deng guang”
digitalWrite(Led,LOW); //熄灭LED
Serial.println("received'guan bi deng guang',command flag'1'");//串口发送received"guan deng",command flag"1"
break;
}
}

5.2 Mind+ 上传模式编程
1、下载及安装软件。下载地址:https://mindplus.cc 详细教程:安装教程
2、切换到“上传模式”。 详细教程:Mind+基础wiki教程-上传模式编程流程
3、点击左下角 扩展 按钮,进入扩展库界面
4、选择 主控板 选项卡下的你正在使用的主控板,arduino、micro:bit、掌控板均支持,这里以uno为例 所以选择 Arduino Uno。在 传感器 选项卡下搜索 I2C语音识别模块,点击加载扩展库。 详细教程:Mind+基础wiki教程-加载扩展库流程
5、进行编程,程序如下图:
6、菜单“连接设备”,“上传到设备”
7、程序上传完毕后,对语音识别模块说出“开灯”、“关灯”即可控制LED模块。详细教程:Mind+基础wiki教程-串口打印
注意:关键词添加完成后,一定要使用"设置完成 开始识别"积木结尾才可以正常识别

5.3 Mind+ Python模式编程(行空板)
Mind+Python模式为完整Python编程,因此需要能运行完整Python的主控板,此处以行空板为例说明
连接图
操作步骤
1、下载及安装官网最新软件。下载地址:https://www.mindplus.cc 详细教程:Mind+基础wiki教程-软件下载安装
2、切换到“Python模式”。“扩展”中选择“官方库”中的“行空板”和“pinpong库”中的”pinpong初始化“和“语音识别模块”。切换模式和加载库的详细操作链接
3、进行编程
4、连接行空板,程序点击运行后,可在终端查看数据。行空板官方文档-行空板快速上手教程 (unihiker.com)
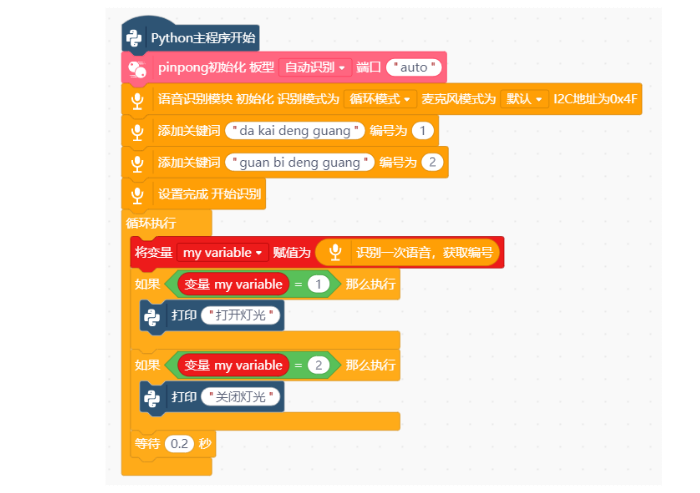
代码编程
以pinpong库为例,行空板官方文档-行空板快速上手教程 (unihiker.com)
# -*- coding: UTF-8 -*-
# MindPlus
# Python
from pinpong.libs.dfrobot_asr import DFRobot_ASR
from pinpong.board import Board
import time
Board().begin()
p_gravityasr = DFRobot_ASR()
p_gravityasr.begin(p_gravityasr.LOOP, p_gravityasr.MIC)
p_gravityasr.add_command("da kai deng guang", 1)
p_gravityasr.add_command("guan bi deng guang", 2)
p_gravityasr.start()
while True:
my_variable = p_gravityasr.read()
if (my_variable == 1):
print("打开灯光")
if (my_variable == 2):
print("关闭灯光")
time.sleep(0.2)
5.4 语音识别模式介绍及使用
本品目前有三种语音识别模式:循环模式、按钮模式、指令模式。(通过 begin() 函数的参数进行设置)
- 识别模式指示灯的亮代表语音识别模块在工作、灭代表语音识别模块在休眠
- 识别模式指示灯的蓝色代表循环模式、绿色代表按钮模式、白色代表指令模式
- 识别模式指示灯闪烁一次表示语音识别模块准确识别到添加的关键词
循环模式
将本品的识别模式设置为循环模式后,识别模式指示灯为常亮蓝色,此时模块一直处于拾音状态,不停的拾取环境中的声音进行分析识别。当识别到录入的关键词后,指示灯会闪烁一次,提示使用者已准确识别。同一时间只能识别一条关键词,待指示灯闪烁后方可进行下次识别。

烧录下列代码:
#include "DFRobot_ASR.h"
DFRobot_ASR asr;
void setup()
{
Serial.begin(9600);
digitalWrite(LED_BUILTIN,LOW); //对 UNO 主控板的板载 LED 初始状态设置为熄灭
asr.begin(asr.LOOP); //1.LOOP 2.BUTTON 3.PASSWORD
asr.addCommand("da kai deng guang",0);
asr.addCommand("guan bi deng guang",1);
asr.start();
Serial.println("Start");
}
void loop()
{
switch(asr.read()) //判断识别内容,在有识别结果的情况下asr.read()会返回识别到的词条编号,否则返回-1
{
case 0: //若是指令“da kai deng guang”
digitalWrite(LED_BUILTIN,HIGH); //点亮板载 LED
Serial.println("received'da kai deng guang',command flag'0'");
break;
case 1: //若是指令“guan bi deng guang”
digitalWrite(LED_BUILTIN,LOW); //熄灭板载 LED
Serial.println("received'guan bi deng guang',command flag'1'");
break;
}
}
mind+ 上传模式:
注意关键词添加完成后,一定要使用设置完成 开始识别积木结尾才可以正常识别
效果如下:
请使用打开灯光、关闭灯光来替代开灯、关灯命令

Mind+ python积木块模式:

Mind+ python代码模式:
# -*- coding: UTF-8 -*-
# MindPlus
# Python
from pinpong.libs.dfrobot_asr import DFRobot_ASR
from pinpong.board import Board
import time
Board().begin()
p_gravityasr = DFRobot_ASR()
p_gravityasr.begin(p_gravityasr.LOOP, p_gravityasr.MIC)
p_gravityasr.add_command("da kai deng guang", 1)
p_gravityasr.add_command("guan bi deng guang", 2)
p_gravityasr.start()
while True:
my_variable = p_gravityasr.read()
if (my_variable == 1):
print("打开灯光")
if (my_variable == 2):
print("关闭灯光")
time.sleep(0.2)
按钮模式
将本品的识别模式设置为按钮模式后,识别模式指示灯为常灭,此时模块处于休眠状态,对环境中的声音完全忽略,在按钮被按下时会激活模块。模块被激活后,指示灯常亮绿色,识别到录入的关键词后,指示灯会闪烁一次,提示使用者已准确识别。同一时间只能识别一条关键词,待指示灯闪烁后方可进行下次识别。
注意:必须按住按钮说话并等待模块识别成功后再松开按钮。当按钮松开后,模块会立即进入休眠,如果在识别过程中松开按钮会导致识别失败。

烧录下列代码:
#include "DFRobot_ASR.h"
DFRobot_ASR asr;
void setup()
{
Serial.begin(9600);
digitalWrite(LED_BUILTIN,LOW); //对 UNO 主控板的板载 LED 初始状态设置为熄灭
asr.begin(asr.BUTTON); //1.LOOP 2.BUTTON 3.PASSWORD
asr.addCommand("da kai deng guang",0);
asr.addCommand("guan bi deng guang",1);
asr.start();
Serial.println("Start");
}
void loop()
{
switch(asr.read()) //判断识别内容,在有识别结果的情况下asr.read()会返回识别到的词条编号,否则返回-1
{
case 0: //若是指令“kai deng”
digitalWrite(LED_BUILTIN,HIGH); //点亮板载 LED
Serial.println("received'da kai deng guang',command flag'0'");
break;
case 1: //若是指令“guan deng”
digitalWrite(LED_BUILTIN,LOW); //熄灭板载 LED
Serial.println("received'guan bi deng guang',command flag'1'");
break;
}
}
mind+ 上传模式:
注意关键词添加完成后,一定要使用设置完成 开始识别积木结尾才可以正常识别
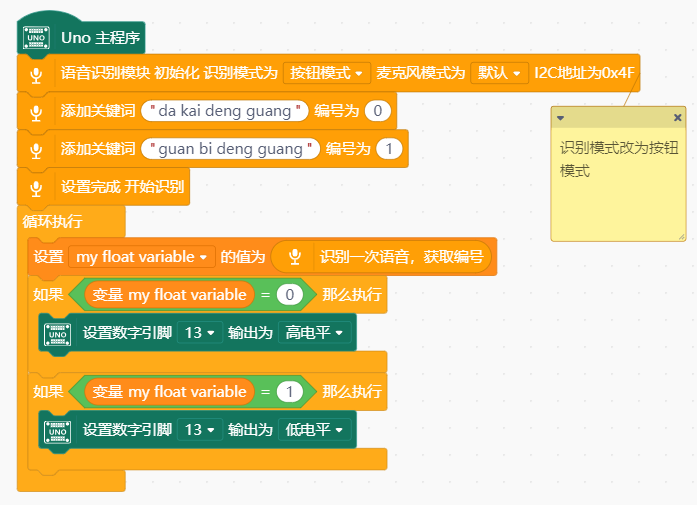
效果如下:
请使用打开灯光、关闭灯光来替代开灯、关灯命令

Mind+ python积木块模式:

Mind+ python代码模式:
# -*- coding: UTF-8 -*-
# MindPlus
# Python
from pinpong.libs.dfrobot_asr import DFRobot_ASR
from pinpong.board import Board
import time
Board().begin()
p_gravityasr = DFRobot_ASR()
p_gravityasr.begin(p_gravityasr.BUTTON, p_gravityasr.MIC)
p_gravityasr.add_command("da kai deng guang", 1)
p_gravityasr.add_command("guan bi deng guang", 2)
p_gravityasr.start()
while True:
my_variable = p_gravityasr.read()
if (my_variable == 1):
print("打开灯光")
if (my_variable == 2):
print("关闭灯光")
time.sleep(0.2)
指令模式
将本品的识别模式设置为指令模式后,识别模式指示灯为常灭,此时模块处于休眠状态,对环境中的声音完全忽略,在说出唤醒关键词后激活模块。模块被激活后,指示灯常亮白色,识别到录入的关键词后,指示灯会闪烁一次,提示使用者已准确识别。同一时间只能识别一条关键词,待指示灯闪烁后方可进行下次识别。唤醒时长为10s。在这10s内,每当识别到添加的关键词后,唤醒时间会刷新。如果10s内没有识别成功。则模块会再次进入休眠状态。
注:指令模式下,默认录入的第一个关键词作为唤醒指令,与指令识别 ID 号顺序无关。

烧录下列代码:
#include "DFRobot_ASR.h"
DFRobot_ASR asr;
void setup()
{
Serial.begin(9600);
digitalWrite(LED_BUILTIN,LOW); //对 UNO 主控板的板载 LED 初始状态设置为熄灭
asr.begin(asr.PASSWORD); //1.LOOP 2.BUTTON 3.PASSWORD
asr.addCommand("xiao zhi",2);
asr.addCommand("da kai deng guang",0);
asr.addCommand("guan bi deng guang",1);
asr.start();
Serial.println("Start");
}
void loop()
{
switch(asr.read()) //判断识别内容,在有识别结果的情况下asr.read()会返回识别到的词条编号,否则返回-1
{
case 0: //若是指令“da kai deng guang”
digitalWrite(LED_BUILTIN,HIGH); //点亮板载 LED
Serial.println("received'da kai deng guang',command flag'0'");
break;
case 1: //若是指令“guan bi deng guang”
digitalWrite(LED_BUILTIN,LOW); //熄灭板载 LED
Serial.println("received'guan bi deng guang',command flag'1'");
break;
}
}
mind+ 上传模式:
注意关键词添加完成后,一定要使用设置完成 开始识别积木结尾才可以正常识别
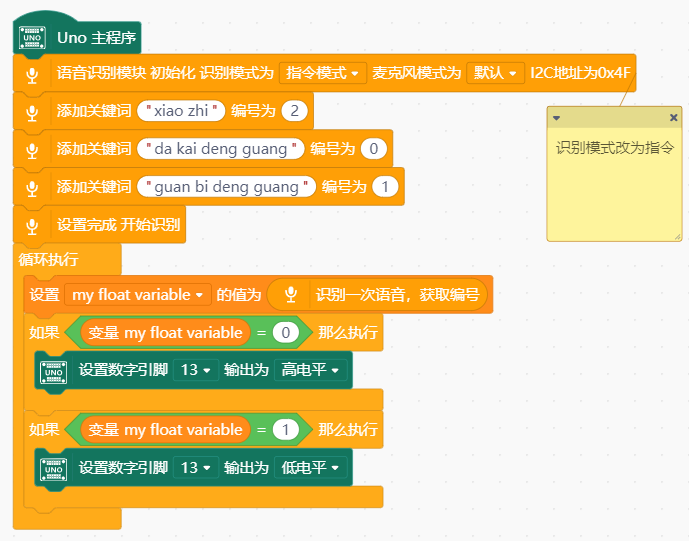
效果如下:
请使用打开灯光、关闭灯光来替代开灯、关灯命令

Mind+ python积木块模式:
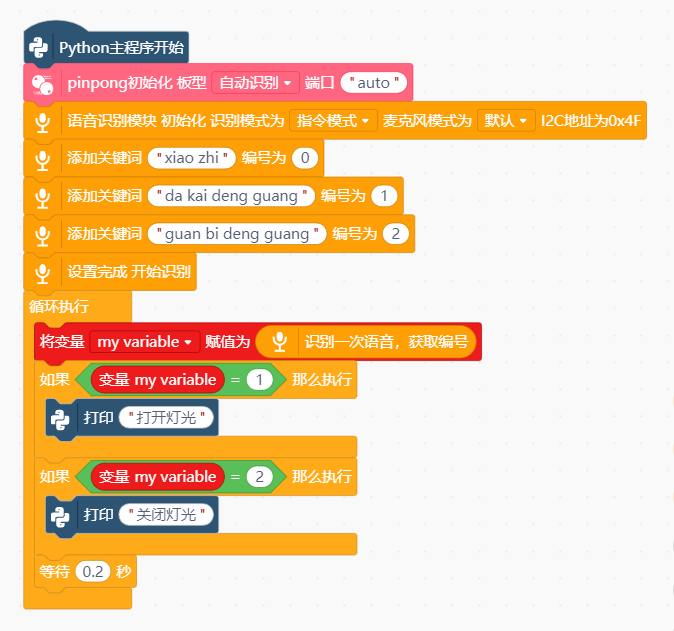
Mind+ python代码模式:
# -*- coding: UTF-8 -*-
# MindPlus
# Python
from pinpong.libs.dfrobot_asr import DFRobot_ASR
from pinpong.board import Board
import time
Board().begin()
p_gravityasr = DFRobot_ASR()
p_gravityasr.begin(p_gravityasr.PASSWORD, p_gravityasr.MIC)
p_gravityasr.add_command("xiao zhi", 0)
p_gravityasr.add_command("da kai deng guang", 1)
p_gravityasr.add_command("guan bi deng guang", 2)
p_gravityasr.start()
while True:
my_variable = p_gravityasr.read()
if (my_variable == 1):
print("打开灯光")
if (my_variable == 2):
print("关闭灯光")
time.sleep(0.2)
5.4 LineIn 接口的使用方法
**LineIn接口:**LineIn 为外界音频输入接口。比如电脑的音频输出接口或手机的耳机接口都可以作为音频输出接口,通过两端 3.5mm 接口线与语音识别模块连接。LineIn 接口只在 MONO 模式下使用。(如下图)



- 连接方法如图:

- 烧录代码:
#include "DFRobot_ASR.h"
DFRobot_ASR asr;
void setup()
{
Serial.begin(9600);
asr.begin(asr.LOOP,asr.MONO); // LineIn接口只在MONO模式下使用
asr.addCommand("bei jing",0); //添加词条"北京",识别号为 0
asr.addCommand("shang hai",1); //添加词条"上海",识别号为 1
asr.start();
Serial.println("Start");
}
void loop()
{
int result = 0;
result = asr.read();
if(result != -1)
{
Serial.print("ASR result is:");
Serial.println(result);//返回识别结果,即识别到的词条编号
}
}
使用 Mind+ 图形化编程时,可通过下面的积木进行模式设置

- 在电脑端录制两段音频,内容为“北京”、“上海”(以下展示是在Windows10操作系统下完成)
打开电脑自带的录音软件,录制两段音频,如下图:

- 点击播放录制的音频
播放录制的音频,音频通过 LineIn 接口输入语音识别模块内,可以在串口监视器中看到音频已经被正确识别并且打印出对应识别号。

6 库函数说明

7 更多应用技巧
在某些场合需要识别一些简单的外文或者纯方言发音的时候,可以用拼音标注的方法来实现。
例如,有些场合需要识别一些简单的英文单词,可以用拼音标注:
one → wan
two → tu
three → si rui
例如,有些场合需要识别一些纯方言发音的词汇,也可以用拼音标注:
在识别精度要求高的场景中,可以增添 “垃圾关键词语”——吸收错误识别
LD3320 采用的识别方式是近似识别,麦克风采集到的声音与录入的词条做对比,相似度高就认为是相同。所以,在使用中可能会出现误识别的现象。这时我们可以在程序中多添加些 “垃圾关键词语”,就可以最大程度避免误识别。
例如,某个应用场景中,需要识别的关键词语是 4 条,“前进”,“后退”,“开门”,“关门”。在把这 4 个关键词语设置进芯片后,可以再另外设置 10~30 个词语进模块芯片,比如“前门”,“后门”,“阿阿阿”,“呜呜”等等。
只有识别结果是 4 个关键词语之内的,才认为识别有效。如果识别结果是“垃圾关键词语”,则说明是其他的声音导致的误识别,程序会重新开始一次识别过程。
更多技巧请戳这里 LD3320_advanced.pdf
8 常见问题
还没有客户对此产品有任何问题,欢迎通过qq或者论坛联系我们!
更多问题及有趣的应用,可以 访问论坛 进行查阅或发帖。
